Generative AI in Systematic Investing: The Sizzle and the Steak
Key Takeaways
- Generative AI gained widespread attention following the debut of ChatGPT by OpenAI in 2022. While the technology may seem new, its origins and applications trace back to the mid-2000s.
- Even though it’s their capacity to produce new realistic content that garners both wonder and concern, the significance and potential impact of Generative AI models extend far beyond their purely generative use cases.
- The source of generative AI’s power is also its limitation. The vast amounts of data such models require for training may not exist for many investment problems. Knowing where, when, and how to successfully apply Generative AI to systematic investing will be a source of competitive edge.
Table of contents
Generative AI: Hardly Out of Nowhere
While the barcode was invented in the late 1940s, most people were unaware of the technology’s existence prior to its widespread adoption in supermarkets decades later. Checkout scanners and their ubiquitous beeps rapidly proceeded to become so engrained in daily life that President George H. W. Bush’s apparent (but misreported) unfamiliarity with the technology at a campaign stop in Florida fueled a narrative that he was disconnected from ordinary voters, likely contributing to his defeat by the up-and-coming challenger, Bill Clinton.1
The idea of interconnected computer networks had been brewing in academic and research circles for decades, with notable developments like ARPANET in the late 1960s and Tim Berners-Lee’s proposal for the World Wide Web in 1989. However, it was the release of Netscape Navigator in December 1994 that made the internet accessible to the public, leading to a rapid expansion of online services and the birth of the dot-com boom.
Figure 1: Worldwide Search Activity for “Generative AI"
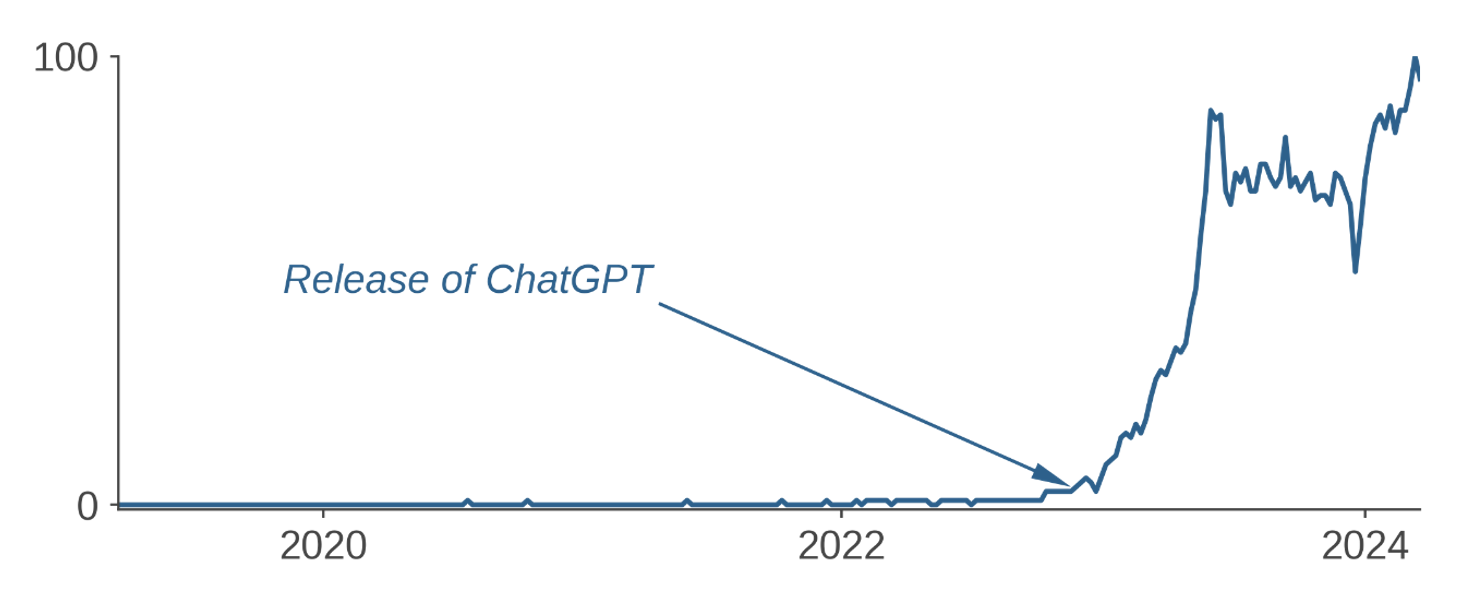
These are not isolated phenomena. A technology often emerges and makes strides for years largely out of public view before capturing mass attention with a prominent milestone or product release, leading to the misconception that it was completely new. Generative AI, a branch of artificial intelligence so named for models that are trained to “generate” new data, has followed a similar path to mainstream consciousness.2
While generative AI surged into the zeitgeist seemingly out of nowhere in late 2022 with OpenAI’s release of ChatGPT (Figure 1), this subfield of artificial intelligence has been around since at least the mid-2000s. If you have ever used Google Translate, Autocomplete, Siri, Alexa or come across a deepfake image or video, then you have seen Generative AI in action.3 While excitement about generative AI is certainly warranted, we find that current speculations about its applicability and promise are in some cases misplaced and in others premature – both broadly speaking as well as in the context of systematic investing.
Legitimate Excitement
The output of generative models has been increasing in sophistication and realism at a truly remarkable pace. While it is their generative applications that have received much of the attention, we believe their potential benefits are dwarfed by those of applications that don’t require creation of new content but where Generative AI can nonetheless excel relative to simpler models – provided certain conditions are met (more on this below).
In active systematic investing, strictly generative use cases are fairly limited – missing data imputation, synthetic data generation, and risk modelling are some of the more frequently mentioned examples. Generative applications of Natural Language Processing (NLP) based on large language models could increase operating efficiency in other parts of the business. The non-generative applications, on the other hand, are potentially far more numerous and could theoretically augment or even replace many of the existing methods employed in modeling alpha, risk, and transaction costs. It is this side of generative AI that we find far more exciting. In order to see why, we need to better understand where generative AI draws its strengths.
Generative models excel at capturing high-dimensional data distributions. To achieve realistic synthesis, these models need to learn and reproduce the intricate structures and relationships present in the data, whether images, text, or other complex information. Put simply, in order to generate something, one needs to understand it on a much deeper level than only to recognize or classify it.4 All of us can tell a cat from a dog, but how many can draw a realistic rendering of either? A generative model able to synthetically construct such images will, after additional tuning, perform better at classifying them than a simpler model trained to perform classification only. Similarly, categorizing excerpts of text based on their sentiment is a much simpler task than that of writing a happy or a melancholy poem based on a simple prompt. Understanding sentiment involves grasping the context in which certain words or phrases appear. Generative models excel in capturing subtle contextual nuances to achieve their semantic understanding.5 Thus, a generative model should achieve superior results in extracting sentiment or in performing other tasks that require understanding the contents of a given body of text.
To summarize, the key advantage of generative models is that because they are constructed to perform the more ambitious task of creating new content, they can perform better at non-generative tasks than simpler models designed only for those less sophisticated purposes. This significantly increases generative AI’s scope of applicability.
Theory Versus Practice
Generative AI’s strengths come with limitations and challenges. But these issues are too dry or complex to garner much attention in wide-eyed popular media coverage.
The models are huge, some containing billions of parameters (or more). As a result, training generative models, i.e., estimating those parameters, requires enormous computational resources and massive amounts of data. While the main obstacle in bringing to bear the requisite computing power has become the price tag, data will, in many contexts, pose a barrier that is insurmountable: the volumes of data required to apply generative AI to some problems may simply not yet exist. Active investing is replete with cases where available data sets are nowhere near the scale needed to train data-hungry generative models. Data availability, in fact, helps to explain why NLP has been one area of focus—there are massive corpora of written and spoken text with which researchers can train sophisticated models before applying them to domain-specific projects. Managers must decide whether to rely on an off-the-shelf “foundation model,” i.e., one that is pre-trained based on publicly available information, or to build a customized model trained from scratch on their own data better reflective of that use case. The former may provide acceptable performance for some applications, such as in quantifying characteristics of text that does not require a lot of domain knowledge to parse or interpret. But where specialized knowledge is a must, generic models will struggle without additional tuning.6 For example, as of this writing, ChatGPT does not recommend itself as a tool to quantify sentiment of earnings call transcripts and instead “humbly” suggests better-suited simpler methods.7
Peculiarities of the active investing context accentuate the importance of design and methodological choices in the application of any machine-learning techniques, including generative AI. The signal-to-noise ratio in forecasting asset returns (and/or various related KPIs) tends to be significantly lower than in many other predictive contexts, the features and rules of the market environment are in constant flux, and players rapidly adapt their behavior in response to other participants. Such characteristics put a premium on judicious engineering, including methods of finding the “right fit” (to avoid both over- and under-fitting), design of input features, optimal use of the available data, etc. Successful application of generative AI in systematic investing, therefore, requires significant investment in specialized expertise.
Conclusion
Generative AI represents a powerful addition to the investor’s toolkit. It is not an utterly new development nor does its main promise lie in its generative functionality. It offers systematic managers new capabilities as well as the potential to improve many of their existing quantitative models. Yet the massive amounts of data required to fuel generative AI’s power also limit its application. In systematic investing, knowing where, when, and how to successfully apply generative AI will demand a combination of model engineering expertise and financial domain knowledge that will represent another source of competitive edge.
SIDEBAR: Generative AI in Broader Context
The field of artificial intelligence got its spark in 1950 with the publication of Alan Turing’s seminal paper, “Computing Machinery and Intelligence.” 8 It was born as an academic discipline at the Dartmouth Conference, organized by John McCarthy, Marvin Minsky, Nathaniel Rochester, and Claude Shannon. Nascent AI efforts in the 1950s followed and focused on simple rules-based systems. Over the subsequent decades, researchers attempted to replicate human expertise in various specific domains with limited success. The field experienced periods of optimism, marked by significant progress and excitement. These were punctuated by “AI winters,” characterized by funding cuts and decreased interest due to unmet expectations and limited progress. AI applications continued to grow over time but remained basic due to limitations in training data and computing power Over the past 20 years, exponential growth in volumes of data and computing power permitted significant increases in AI sophistication and capabilities. Methodological breakthroughs were just as important to progress. One of these was Ian Goodfellow’s eureka moment during a casual gathering with friends at a Montreal bar in 2014. What if you pitted two neural networks against each other, he wondered, one generating synthetic data and the other discriminating whether that output is real or fake? The adversarial dynamic between them would eventually converge when the generator creates output so realistic that the discriminator can no longer tell it apart from the real thing. This groundbreaking idea gave rise to Generative Adversarial Networks (GANs), which have since revolutionized many areas of machine learning, opening up new frontiers in data generation, image synthesis, and beyond. GANs, Transformers, and many other innovations have thrust the field forward, enabling machines to perform increasingly complex tasks, matching and at times exceeding human capabilities. |